Veo 3.1 Prompt Guide: Write Prompts That Actually Work
A practical Veo 3.1 prompt guide: the seven-part structure, camera motion terms, audio cues, and real before-and-after clips from $0.10 per video.
原文は en

A Veo 3.1 prompt is a short scene description that tells Google's video model what to shoot and how to shoot it. The models treat your text like a director's brief: they read subject, action, style, camera work, composition, lens choice, and lighting out of it, then fill in everything you didn't specify with their own guesses. Good prompting is mostly about leaving fewer things to guess.
The quick version, if you only read one paragraph: describe one subject doing one action, then add the camera. A working template is "[shot type] of [subject] [doing action] in [setting], [camera movement], [lens or focus], [lighting and mood]". That single habit, adding the camera and light, closes most of the gap between a boring clip and a usable one. Everything below is detail and evidence.
I've been running Veo 3.1 daily on BananaBanana since we launched video generation, and the difference between a lazy prompt and a structured one is bigger here than in any image model I use. Images forgive vagueness. Video punishes it twice, once in the frame and once in the motion.
What makes a good Veo 3.1 prompt?
According to Google's Veo documentation, a strong prompt covers seven elements: subject, action, style, camera positioning, composition, focus and lens effects, and ambiance. You don't need all seven every time. You do need to know which ones you're skipping, because the model will improvise the rest.
| Element | What it controls | Example phrase |
|---|---|---|
| Subject | Who or what is on screen | "an elderly potter with clay-stained hands" |
| Action | What happens during the clip | "shaping a bowl on a spinning wheel" |
| Style | Overall aesthetic | "cinematic documentary style" |
| Camera | Position and movement | "slow dolly-in at eye level" |
| Composition | Framing | "close-up" |
| Lens / focus | Optical character | "shallow depth of field" |
| Ambiance | Light and color mood | "warm window light, dust in the air" |
Order matters less than people think. I usually front-load subject and action because that's what the model anchors on, then stack the camera and light at the end. What matters more is specificity: "a horse" gives the model a coin flip between forty breeds, while "a chestnut Arabian horse" doesn't.
One honest caveat. Veo 3.1 has a prompt rewriter on Google's side that expands short prompts before generation, and you can't fully see what it added. Short prompts sometimes come back with details you never asked for. Writing the detail yourself is how you take that decision away from the rewriter.

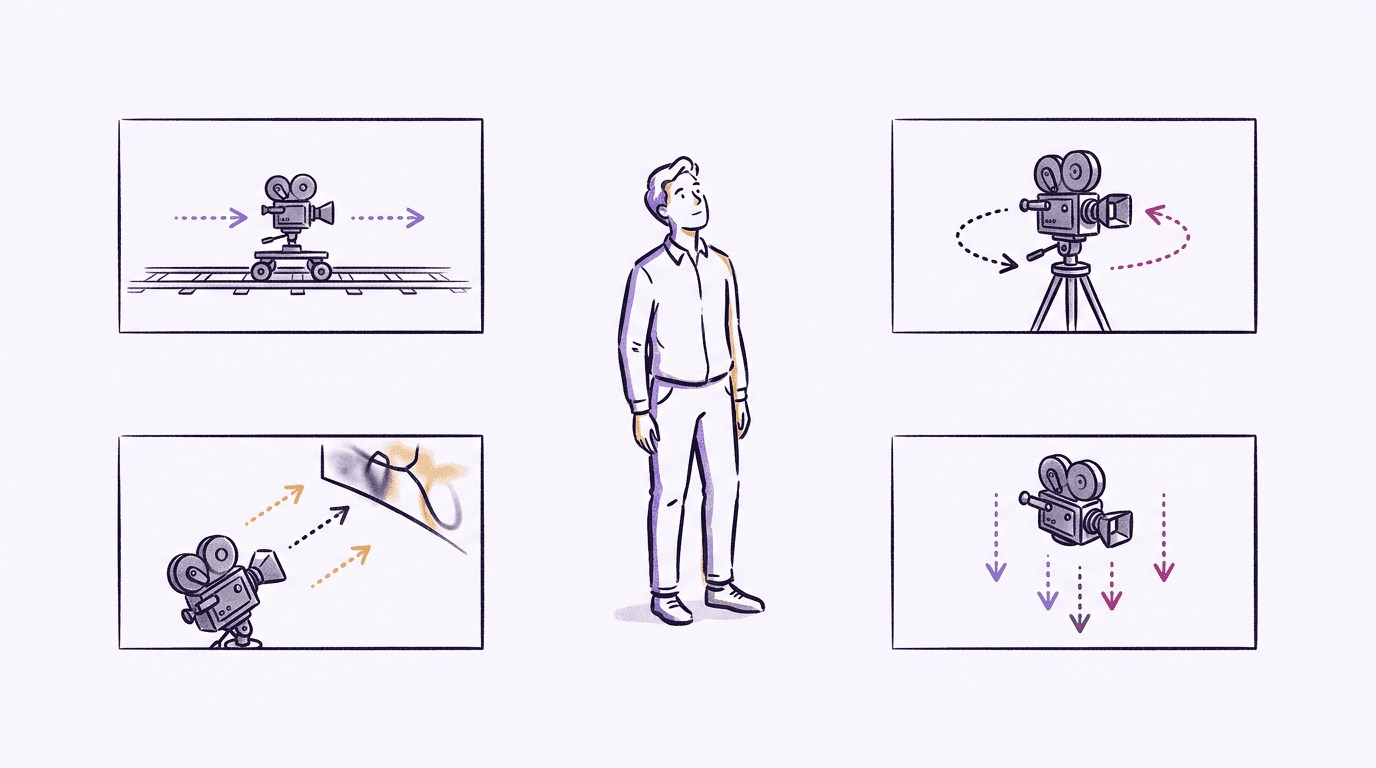
How do you control the camera in Veo 3.1?
Camera language is the highest-leverage part of a Veo 3.1 prompt, and it's the part most people leave out. The model understands standard film vocabulary, so use it literally.
For position: aerial view, eye-level, low-angle shot, top-down shot, over-the-shoulder. For movement: dolly in or out, tracking shot, pan left or right, tilt up, slow zoom, POV shot. For framing: extreme close-up, close-up, medium shot, wide shot, establishing shot. For optics: shallow focus, deep focus, macro lens, wide-angle lens, soft focus.
Two practical rules from our generations. First, one camera move per clip. A prompt asking for "a pan that becomes a dolly-in and then tilts up" usually gets you one of the three, chosen at random, or a mushy compromise. Clips are 4 to 8 seconds; there's room for one move done well. Second, motion verbs beat camera nouns when they conflict. If your subject "sprints" but the camera is "static wide shot", expect the model to prioritize the sprint and drift the camera anyway. Make them agree.
Lighting works the same way: name it like a cinematographer would. "Golden hour backlight", "cool blue moonlight", "harsh overhead fluorescent", "flickering torchlight" all read reliably. Vague mood words like "beautiful lighting" read as nothing.
Before and after: the same idea, two prompts
Talk is cheap, so here's the same scene generated twice with Veo 3.1 Fast on BananaBanana, silent, 6 seconds, 720p. Total cost for both demos: about $1.
First, the prompt everyone writes on day one. Just "A horse running on a beach":
It's fine. It's also generic: default framing, default light, motion that wanders. Now the same idea rewritten with the seven-element structure: "A chestnut Arabian horse gallops along wet sand at golden hour, kicking up spray, low-angle tracking shot moving alongside the horse, shallow depth of field, warm backlit rim light, cinematic 35mm look":
Same subject, same model, same price. The second clip has a deliberate camera, a consistent light direction, and spray catching the backlight, all of which were words in the prompt rather than luck. Both clips are exactly what came back on the first attempt; no rerolls, no cherry-picking.
If you're starting from a photo instead of text, the mechanics change a little (your image locks the first frame and the prompt describes only motion). We covered that workflow separately in the image to video guide.
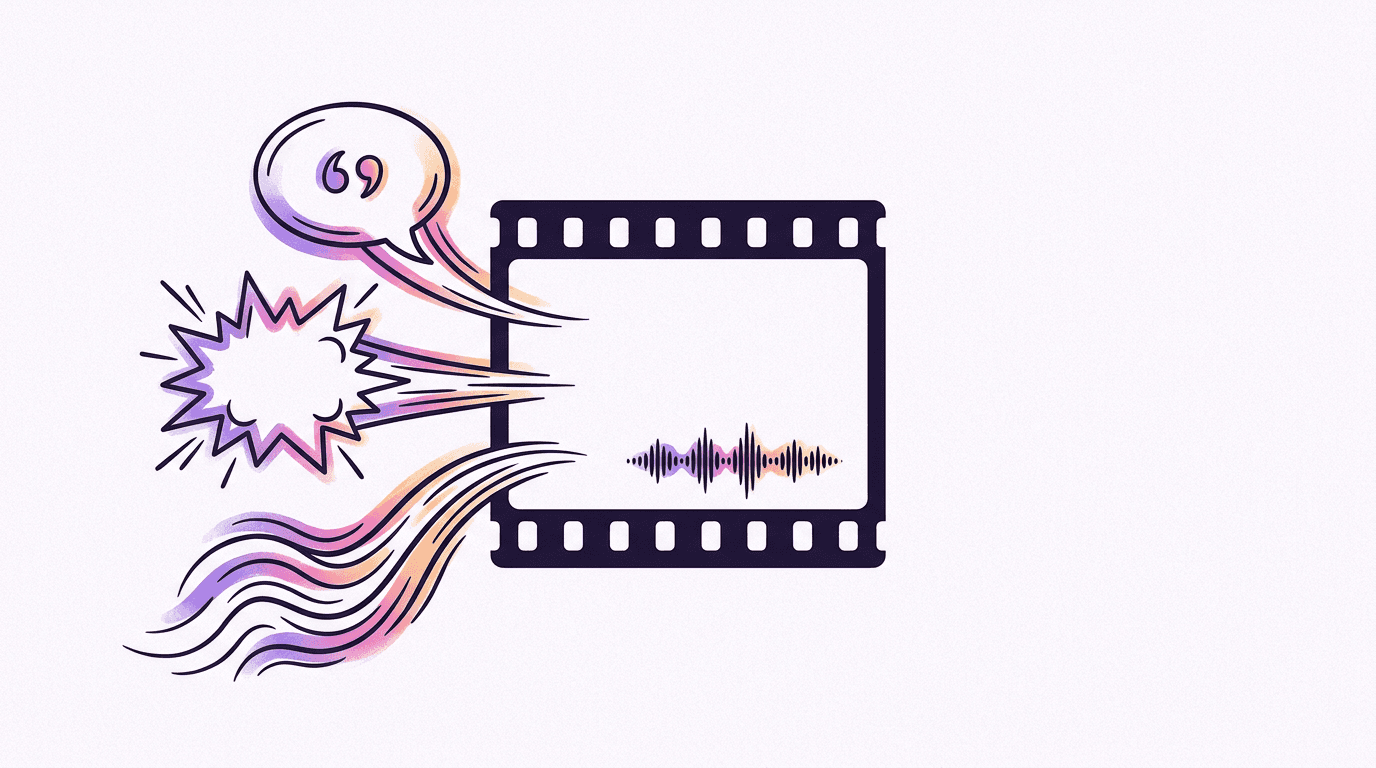
How do you prompt audio in Veo 3.1?
Veo 3.1 generates native audio, and per Google's docs it's always on in the API: dialogue, sound effects, and ambient noise, synchronized to the picture. You control each with a different text convention.
- Dialogue goes in quotes, attached to a speaker: A man murmurs, "This must be it."
- Sound effects are stated as events: "tires screeching", "waves crashing against rocks".
- Ambience is described as atmosphere: "faint hum of fluorescent lights", "distant seagulls".
Google's own example prompt shows the pattern: "A close up of two people staring at a cryptic drawing on a wall, torchlight flickering. A man murmurs, 'This must be it.'" The dialogue quote produces lip-synced speech, and "flickering" plus "torchlight" seeds the room tone.
Keep spoken lines short. In our tests anything past roughly a dozen words per line risks the tail getting clipped or rushed inside an 8-second clip. And write dialogue for one or two speakers, not a crowd; overlapping voices come out muddy.
On BananaBanana audio is a toggle, and it's priced separately because Google bills it separately: an 8-second Veo 3.1 Fast clip costs $0.70 silent or $1.00 with audio at 720p or 1080p. The demos above are silent on purpose, which is the honest budget move when a clip is destined for muted autoplay anyway. (If you want sound on every clip by default, the Omni Flash model takes the opposite approach: audio always on, $1 flat.)
Negative prompts, durations, and what Veo 3.1 costs
The negative prompt situation is genuinely confusing, so here's what we see from the API side. The Gemini API docs for Veo 3.1 don't document a negative prompt parameter. The Vertex AI endpoint, which is what BananaBanana runs on, does accept negativePrompt, and in our generations it measurably steers output. So the field exists in our generator and it works; just don't expect it to behave like a hard filter.
Writing negatives has one counterintuitive rule from Google's prompt guidance: never write "no" or "don't" in the negative field. List the unwanted things as plain nouns. "Cartoon, low quality, text overlay, watermark" works; "no cartoons" can backfire because the word "cartoon" is still in play.
Durations and formats, per Google's docs and our production setup: clips run 4, 6, 7, or 8 seconds at 16:9 or 9:16, with 720p, 1080p, and 4K output. The 8-second length is required for 1080p, 4K, reference images, and extension. Extension is Veo's sleeper feature: each request adds 7 seconds, up to 20 times, which is how you get past two minutes from one prompt chain.
Current BananaBanana pricing for an 8-second 720p clip:
| Model | Silent | With audio |
|---|---|---|
| Veo 3.1 Lite | $0.20 | $0.36 |
| Veo 3.1 Fast | $0.70 | $1.00 |
| Veo 3.1 | $1.40 | $3.00 |
A 4-second silent Lite clip is $0.10, which happens to be exactly the free balance every new account gets. So your first Veo video costs nothing, and honestly, Lite at 720p is good enough to learn prompt structure on before you spend real money on Fast or the full model. Full price grid is on the pricing page.
My default workflow: draft the prompt on Lite, iterate until the motion and framing hold, then rerun the final prompt once on Fast or Veo 3.1. Prompt quality transfers across the tier almost perfectly; render quality is what you're paying for.
FAQ
What is the best prompt structure for Veo 3.1?
Subject, action, style, camera, composition, lens, ambiance, in roughly that order. A compact template: "[shot type] of [subject] [action] in [setting], [camera move], [lens], [lighting]". Specific nouns beat adjectives, and one camera move per clip beats three.
Does Veo 3.1 support negative prompts?
On Vertex AI, yes: the negativePrompt parameter is accepted and works, though the Gemini API docs don't list it for Veo 3.1. Write negatives as plain nouns ("cartoon, blurry, watermark"), never as "no X" sentences.
How do I make Veo 3.1 generate speech?
Put the line in quotes and attach it to a speaker inside the prompt: A woman whispers, "We're not alone." Veo lip-syncs short lines well; keep dialogue under about a dozen words per clip.
How long can a Veo 3.1 video be?
Base clips are 4 to 8 seconds. With extension (7 extra seconds per request, up to 20 extensions per Google's docs) a single chain can reach 148 seconds at 720p.
How much does one Veo 3.1 video cost?
On BananaBanana, from $0.10 (4-second silent Veo 3.1 Lite at 720p) to $4.40 (8-second 4K Veo 3.1 with audio). The mid-range default, an 8-second silent Fast clip, is $0.70.